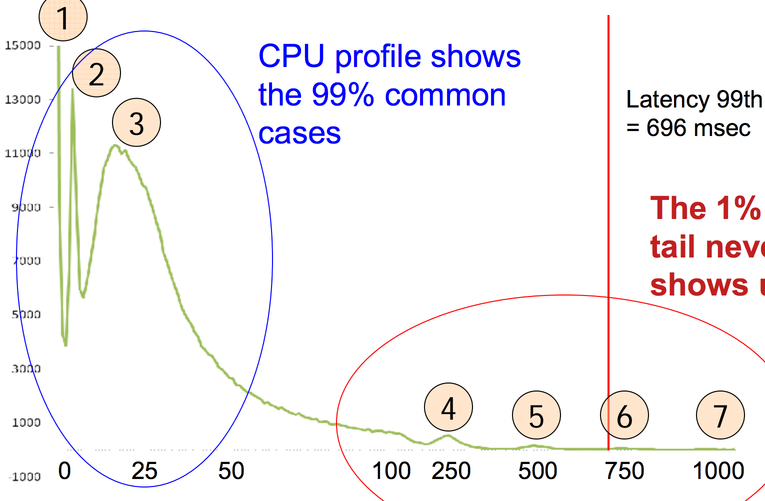
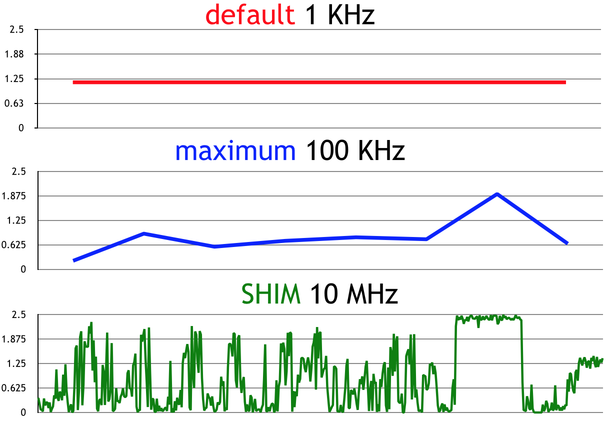
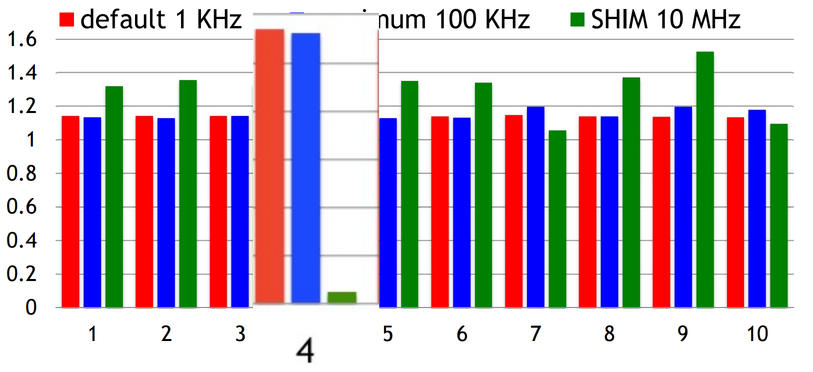
Tavish Armstrong has a great document where he describes how and when he learned the programming skills he has. I like this idea because I’ve found that the paths that people take to get into programming are much more varied than stereotypes give credit for, and I think it’s useful to see that there are many possible paths into programming.
Personally, I spent a decade working as an electrical engineer before taking a programming job. When I talk to people about this, they often want to take away a smooth narrative of my history. Maybe it’s that my math background gives me tools I can apply to a lot of problems, maybe it’s that my hardware background gives me a good understanding of performance and testing, or maybe it’s that the combination makes me a great fit for hardware/software co-design problems. People like a good narrative. One narrative people seem to like is that I’m a good problem solver, and that problem solving ability is generalizable. But reality is messy. Electrical engineering seemed like the most natural thing in the world, and I picked it up without trying very hard. Programming was unnatural for me, and didn’t make any sense at all for years. If you believe in the common “you either have it or you don’t” narrative about programmers, I definitely don’t have it. And yet, I now make a living programming, and people seem to be pretty happy with the work I do.
How’d that happen? Well, if we go back to the beginning, before becoming a hardware engineer, I spent a fair amount of time doing failed kid-projects (e.g., writing a tic-tac-toe game and AI) and not really “getting” programming. I do sometimes get a lot of value out of my math or hardware skills, but I suspect I could teach someone the actually applicable math and hardware skills I have in less than a year. Spending five years in a school and a decade in industry to pick up those skills was a circuitous route to getting where I am. Amazingly, I’ve found that my path has been more direct than that of most of my co-workers, giving the lie to the narrative that most programmers are talented whiz kids who took to programming early.
And while I only use a small fraction of the technical skills I’ve learned on any given day, I find that I have a meta-skill set that I use all the time. There’s nothing profound about the meta-skill set, but because I often work in new (to me) problem domains, I find my meta skillset to be more valuable than my actual skills. I don’t think that you can communicate the importance of meta-skills (like communication) by writing a blog post any more than you can explain what a monad is by saying that it’s like a burrito. That being said, I’m going to tell this story anyway.
Ineffective fumbling (1980s - 1996)
Many of my friends and I tried and failed multiple times to learn how to program. We tried BASIC, and could write some simple loops, use conditionals, and print to the screen, but never figured out how to do anything fun or useful.
We were exposed to some kind of lego-related programming, uhhh, thing in school, but none of us had any idea how to do anything beyond what was in the instructions. While it was fun, it was no more educational than a video game and had a similar impact.
One of us got a game programming book. We read it, tried to do a few things, and made no progress.
High school (1996 - 2000)
Our ineffective fumbling continued through high school. Due to an interest in gaming, I got interested in benchmarking, which eventually led to learning about CPUs and CPU microarchitecture. This was in the early days of Google, before Google Scholar, and before most CS/EE papers could be found online for free, so this was mostly material from enthusiast sites. Luckily, the internet was relatively young, as were the users on the sites I frequented. Much of the material on hardware was targeted at (and even written by) people like me, which made it accessible. Unfortunately, a lot of the material on programming was written by and targeted at professional programmers, things like Paul Hsieh’s optimization guide. There were some beginner-friendly guides to programming out there, but my friends and I didn’t stumble across them.
We had programming classes in high school: an introductory class that covered Visual Basic and an AP class that taught C++. Both classes were taught by someone who didn’t really know how to program or how to teach programming. My class had a couple of kids who already knew how to program and were making good money doing programming competitions on topcoder, but they failed to test out of the intro class because that test included things like a screenshot of the VB6 IDE, where you got a point for correctly identifying what each button did. The class taught about as much as you’d expect from a class where the pre-test involved identifying UI elements from an IDE.
The AP class the year after was similarly effective. About halfway through the class, a couple of students organized an independent study group which worked through an alternate textbook because the class was clearly not preparing us for the AP exam. I passed the AP exam because it was one of those multiple choice tests that’s possible to pass without knowing the material.
Although I didn’t learn much, I wouldn’t have graduated high school if not for AP classes. I failed enough individual classes that I almost didn’t have enough credits to graduate. I got those necessary credits for two reasons: first, a lot of the teachers had a deal where, if you scored well on the AP exam, they would give you a passing grade in the class (usually an A, but sometimes a B). Even that wouldn’t have been enough if my chemistry teacher hadn’t also changed my grade to a passing grade when he found out I did well on the AP chemistry test.
Other than not failing out of high school, I’m not sure I got much out of my AP classes. My AP CS class actually had a net negative effect on my learning to program because the AP test let me opt out of the first two intro CS classes in college (an introduction to programming and a data structures course). In retrospect, I should have taken the intro classes, but I didn’t, which left me with huge holes in my knowledge that I didn’t really fill in for nearly a decade.
College (2000 - 2003)
Because I’d nearly failed out of high school, there was no reasonable way I could have gotten into a “good” college. Luckily, I grew up in Wisconsin, a state with a “good” school that used a formula to determine who would automatically get admitted: the GPA cutoff depended on standardized test scores, and anyone with standardized test scores above a certain mark was admitted regardless of GPA. During orientation, I talked to someone who did admissions and found out that my year was the last year they used the formula.
I majored in computer engineering and math for reasons that seem quite bad in retrospect. I had no idea what I really wanted to study. I settled on either computer engineering or engineering mechanics because both of those sounded “hard”.
I made a number of attempts to come up with better criteria for choosing a major. The most serious was when I spent a week talking to professors in an attempt to find out what day-to-day life in different fields was like. That approach had two key flaws. First, most professors don’t know what it’s like to work in industry; now that I work in industry and talk to folks in academia, I see that most academics who haven’t done stints in industry have a lot of misconceptions about what it’s like. Second, even if I managed to get accurate descriptions of different fields, it turns out that there’s a wide body of research that indicates that humans are basically hopeless at predicting which activities they’ll enjoy. Ultimately, I decided by coin flip.
Math
I wasn’t planning on majoring in math, but my freshman intro calculus course was so much fun that I ended up adding a math major. That only happened because a high-school friend of mine passed me the application form for the honors calculus sequence because he thought I might be interested in it (he’d already taken the entire calculus sequence as well as linear algebra). The professor for the class covered the material at an unusually fast pace: he finished what was supposed to be a year-long calculus textbook in part-way through the semester and then lectured on his research for the rest of the semester. The class was theorem-proof oriented and didn’t involve any of that yucky memorization that I’d previously associated with math. That was the first time I’d found school engaging in my entire life and it made me really look forward to going to math classes. I later found out that non-honors calculus involved a lot of memorization when the engineering school required me to go back and take calculus II, which I’d skipped because I’d already covered the material in the intro calculus course.
If I hadn’t had a friend drop the application for honors calculus in my lap, I probably wouldn’t have majored in math and it’s possible I never would have found any classes that seemed worth attending. Even as it was, all of the most engaging undergrad professors I had were math professors and I mostly skipped my other classes. I don’t know how much of that was because my math classes were much smaller, and therefore much more customized to the people in the class (computer engineering was very trendy at the time, and classes were overflowing), and how much was because these professors were really great teachers.
Although I occasionally get some use out of the math that I learned, most of the value was in becoming confident that I can learn and work through the math I need to solve any particular problem.
Engineering
In my engineering classes, I learned how to debug and how computers work down to the transistor level. I spent a fair amount of time skipping classes and reading about topics of interest in the library, which included things like computer arithmetic and circuit design. I still have fond memories of Koren’s Computer Arithmetic Algorithms, Chandrakasan et al.’s Design of High-Performance Microprocessor Circuits. I also started reading papers; I spent a lot of time in libraries reading physics and engineering papers that mostly didn’t make sense to me. The notable exception were systems papers, which I found to be easy reading. I distinctly remember reading the Dynamo paper (this was HP’s paper on JITs, not the more recent Amazon work of the same name), but I can’t recall any other papers I read back then.
Internships
I had two internships, one at Micron where I “worked on” flash memory, and another at IBM where I worked on the POWER6. The Micron internship was a textbook example of a bad internship. When I showed up, my manager was surprised that he was getting an intern and had nothing for me to do. After a while (perhaps a day), he found an assignment for me: press buttons on a phone. He’d managed to find a phone that used Micron flash chips; he handed it to me, told me to test it, and walked off.
After poking at the phone for an hour or two and not being able to find any obvious bugs, I walked around and found people who had tasks I could do. Most of them were only slightly less manual than “testing” a phone by mashing buttons, but I did one not-totally-uninteresting task, which was to verify that a flash chip’s controller behaved correctly. Unlike my other tasks, this was amenable to automation and I was able to write a perl script to do the testing for me.
I chose perl because someone had a perl book on their desk that I could borrow, which seemed like as good a reason as any at the time. I called up a friend of mine to tell him about this great “new” language and we implemented age of renaissance, a boardgame we’d played in high school. We didn’t finish, but perl was easy enough to use that we felt like we could write a program that actually did something interesting.
Besides learning perl, I learned that I could ask people for books and read them, and I spent most of the rest of my internship half keeping an eye on a manual task while reading the books people had lying around. Most of the books had to do with either analog circuit design or flash memory, so that’s what I learned. None of the specifics have really been useful to me in my career, but I learned two meta-items that were useful.
First, no one’s going to stop you from spending time reading at work or spending time learning (on most teams). Micron did its best to keep interns from learning by having a default policy of blocking interns from having internet access (managers could override the policy, but mine didn’t), but no one will go out of their way to prevent an intern from reading books when their other task is to randomly push buttons on a phone.
Second, I learned that there are a lot of engineering problems we can solve without anyone knowing why. One of the books I read was a survey of then-current research on flash memory. At the time, flash memory relied on some behaviors that were well characterized but not really understood. There were theories about how the underlying physical mechanisms might work, but determining which theory was correct was still an open question.
The next year, I had a much more educational internship at IBM. I was attached to a logic design team on the POWER6, and since they didn’t really know what to do with me, they had me do verification on the logic they were writing. They had a relatively new tool called SixthSense, which you can think of as a souped-up quickcheck. The obvious skill I learned was how to write tests using a fancy testing framework, but the meta-thing I learned which has been even more useful is the fact that writing a test-case generator and a checker is often much more productive than the manual test-case writing that passes for automated testing in most places.
The other thing I encountered for the first time at IBM was version control (CVS, unfortunately). Looking back, I find it a bit surprising that not only did I never use version control in any of my classes, but I’d never met any other students who were using version control. My IBM internship was between undergrad and grad school, so I managed to get a B.S. degree without ever using or seeing anyone use version control.
Computer Science
I took a couple of CS classes. The first was algorithms, which was poorly taught and so heavily curved as a result that I got an A despite not learning anything at all. The course involved no programming and while I could have done some implementation in my free time, I was much more interested in engineering and didn’t try to apply any of the material.
The second course was databases. There were a couple of programming projects, but they were all projects where you got some scaffolding and only had to implement a few key methods to make things work, so it was possible to do ok without having any idea how to program. I got involved in a competition to see who could attend fewest possible classes, didn’t learn anything, and scraped by with a B.
Grad school (2003 - 2005)
After undergrad, I decided to go to grad school for a couple of silly reasons. One was a combination of “why not?” and the argument that most of professors gave, which was that you’ll never go if you don’t go immediately after undergrad because it’s really hard to go back to school later. But the reason that people don’t go back later is because they have more information (they know what both school and work are like), and they almost always choose work! The other major reason was that I thought I’d get a more interesting job with a master’s degree. That’s not obviously wrong, but it appears to be untrue in general for people going into electrical engineering and programming.
I don’t know that I learned anything that I use today, either in the direct sense or in a meta sense. I had some great professors and I made some good friends, but I think that this wasn’t a good use of time because of two bad decisions I made at the age of 19 or 20. Rather than attended a school that had a lot of people working in an area I was interested in, I went with a school that gave me a fellowship that only had one person working in an area I was really interested. That person left just before I started.
I ended up studying optics, and while learning a new field was a lot of fun, the experience was of no particular value to me, and I could have had fun studying something I had more of an interest in.
While I was officially studying optics, I still spent a lot of time learning unrelated things. At one point, I decided I should learn Lisp or Haskell, probably because of something Paul Graham wrote. I couldn’t find a Lisp textbook in the library, but I found a Haskell textbook. After I worked through the exercises, I had no idea how to accomplish anything practical. But I did learn about list comprehensions and got in the habit of using higher-order functions.
Based on internet comments and advice, I had the idea learning more languages would teach me how to be a good programmer so I worked through introductory books on Python and Ruby. As far as I can tell, this taught me basically nothing useful and I would have been much better off learning about a specific area (like algorithms or networking) than learning lots of languages.
First real job (2005 - 2013)
Towards the end of grad school, I mostly looked for, and found, electrical/computer engineering jobs. The one notable exception was Google, which called me up in order to fly me out to Mountain View for an interview. I told them that they probably had the wrong person because they hadn’t even done a phone screen, so they offered to do a phone interview instead. I took the phone interview expecting to fail because I didn’t have any CS background, and I failed as expected. In retrospect, I should have asked to interview for a hardware position, but at the time I didn’t know they had hardware positions, even though they’d been putting together their own servers and designing some of their own hardware for years.
Anyway, I ended up at a little chip company called Centaur. I was hesitant about taking the job because the interview was the easiest interview I had at any company, which made me wonder if they had a low hiring bar, and therefore relatively weak engineers. It turns out that, on average, that’s the best group of people I’ve ever worked with. I didn’t realize it at the time, but this would later teach me that companies that claim to have brilliant engineers because they have super hard interviews are full of it, and that the interview difficulty one-upmanship a lot of companies promote is more of a prestige play than anything else.
But I’m getting ahead of myself – my first role was something they call “regression debug”, which included debugging test failures for both newly generated tests as well as regression tests. The main goal of this job was to teach new employees the ins-and-outs of the x86 architecture. At the time, Centaur’s testing was very heavily based on chip-level testing done by injecting real instructions, interrupts, etc., onto the bus, so debugging test failures taught new employees everything there is to know about x86.
The Intel x86 manual is thousands of pages long and it isn’t sufficient to implement a compatible x86 chip. When Centaur made its first x86 chip, they followed the Intel manual in perfect detail, and left all instances of undefined behavior up to individual implementors. When they got their first chip back and tried it, they found that some compilers produced code that relied on the behavior that’s technically undefined on x86, but happened to always be the same on Intel chips. While that’s technically a compiler bug, you can’t ship a chip that isn’t compatible with actually existing software, and ever since then, Centaur has implemented x86 chips by making sure that the chips match the exact behavior of Intel chips, down to matching officially undefined behavior.
For years afterwards, I had encyclopedic knowledge of x86 and could set bits in control registers and MSRs from memory. I didn’t have a use for any of that knowledge at any future job, but the meta-skill of not being afraid of low-level hardware comes in handy pretty often, especially when I run into compiler or chip bugs. People look at you like you’re a crackpot if you say you’ve found a hardware bug, but because we were so careful about characterizing the exact behavior of Intel chips, we would regularly find bugs and then have discussions about whether we should match the bug or match the spec (the Intel manual).
The other thing I took away from the regression debug experience was a lifelong love of automation. Debugging often involves a large number of mechanical steps. After I learned enough about x86 that debugging became boring, I started automating debugging. At that point, I knew how to write simple scripts but didn’t really know how to program, so I wasn’t able to totally automate the process. However, I was able to automate enough that, for 99% of failures, I just had to glance at a quick summary to figure out what the bug was, rather than spend what might be hours debugging. That turned what was previously a full-time job into something that took maybe 30-60 minutes a day (excluding days when I’d hit a bug that involved some obscure corner of x86 I wasn’t already familiar with, or some bug that my script couldn’t give a useful summary of).
At that point, I did two things that I’d previously learned in internships. First, I started reading at work. I began with online commentary about programming, but there wasn’t much of that, so I asked if I could expense books and read them at work. This seemed perfectly normal because a lot of other people did the same thing, and there were at least two people who averaged more than one technical book per week, including one person who averaged a technical book every 2 or 3 days.
I settled in at a pace of somewhere between a book a week and a book a month. I read a lot of engineering books that imparted some knowledge that I no longer use, now that I spend most of my time writing software; some “big idea” software engineering books like Design Patterns and Refactoring, which I didn’t really appreciate because I was just writing scripts; and a ton of books on different programming languages, which doesn’t seem to have had any impact on me.
The only book I read back then that changed how I write software in a way that’s obvious to me was The Design of Everyday Things. The core idea of the book is that while people beat themselves up for failing to use hard-to-understand interfaces, we should blame designers for designing poor interfaces, not users for failing to use them.
If you ever run into a door that you incorrectly try to pull instead of push (or vice versa) and have some spare time, try watching how other people use the door. Whenever I do this, I’ll see something like half the people who try the door use it incorrectly. That’s a design flaw!
The Design of Everyday Things has made me a lot more receptive to API and UX feedback, and a lot less tolerant of programmers who say things like “it’s fine – everyone knows that the arguments to foo and bar just have to be given in the opposite order” or “Duh! Everyone knows that you just need to click on the menu X, select Y, navigate to tab Z, open AA, go to tab AB, and then slide the setting to AC.”
I don’t think all of that reading was a waste of time, exactly, but I would have been better off picking a few sub-fields in CS or EE and learning about them, rather than reading the sorts of books O’Reilly and Manning produce.
It’s not that these books aren’t useful, it’s that almost all of them are written to make sense without any particular background beyond what any random programmer might have, and you can only get so much out of reading your 50th book targeted at random programmers. IMO, most non-academic conferences have the same problem. As a speaker, you want to give a talk that works for everyone in the audience, but a side effect of that is that many talks have relatively little educational value to experienced programmers who have been to a few conferences.
I think I got positive things out of all that reading as well, but I don’t know yet how to figure out what those things are.
As a result of my reading, I also did two things that were, in retrospect, quite harmful.
One was that I really got into functional programming and used a functional style everywhere I could. Immutability, higher-order X for any possible value of X, etc. The result was code that I could write and modify quickly that was incomprehensible to anyone but a couple of coworkers who were also into functional programming.
The second big negative was that I became convinced that perl was causing us a lot of problems. We had perl scripts that were hard to understand and modify. They’d often be thousands of lines of code with only one or two functions and no tests which used every obscure perl feature you could think of. Static! Magic sigils! Implicit everything! You name it, we used it. For me, the last straw was when I inserted a new function between two functions which didn’t explicitly pass any arguments and return values – and broke the script because one of the functions was returning a value into an implicit variable which was getting read by the next function. By putting another function in between the two closely coupled functions, I broke the script.
After that, I convinced a bunch of people to use Ruby and started using it myself. The problem was that I only managed to convince half of my team to do this The other half kept using Perl, which resulted in language fragmentation. Worse yet, in another group, they also got fed up with Perl, but started using Python, resulting in the company having code in Perl, Python, and Ruby.
Centaur has an explicit policy of not telling people how to do anything, which precludes having team-wide or company-wide standards. Given the environment, using a “better” language seemed like a natural thing to do, but I didn’t recognize the cost of fragmentation until, later in my career, I saw a company that uses standardization to good effect.
Anyway, while I was causing horrific fragmentation, I also automated away most of my regression debug job. I got bored of spending 80% of my time at work reading and I started poking around for other things to do, which is something I continued for my entire time at Centaur. I like learning new things, so I did almost everything you can do related to chip design. The only things I didn’t do were circuit design (the TL of circuit design didn’t want a non-specialist interfering in his area) and a few roles where I was told “Dan, you can do that if you really want to, but we pay you too much to have you do it full-time.”
If I hadn’t interviewed regularly (about once a year, even though I was happy with my job), I probably would’ve wondered if I was stunting my career by doing so many different things, because the big chip companies produce specialists pretty much exclusively. But in interviews I found that my experience was valued because it was something they couldn’t get in-house. The irony is that every single role I was offered would have turned me into a specialist. Big chip companies talk about wanting their employees to move around and try different things, but when you dig into what that means, it’s that they like to have people work one very narrow role for two or three years before moving on to their next very narrow role.
For a while, I wondered if I was doomed to either eventually move to a big company and pick up a hyper-specialized role, or stay at Centaur for my entire career (not a bad fate – Centaur has, by far, the lowest attrition rate of any place I’ve worked because people like it so much). But I later found that software companies building hardware accelerators actually have generalist roles for hardware engineers, and that software companies have generalist roles for programmers, although that might be a moot point since most software folks would probably consider me an extremely niche specialist.
Regardless of whether spending a lot of time in different hardware-related roles makes you think of me as a generalist or a specialist, I picked up a lot of skills which came in handy when I worked on hardware accelerators, but that don’t really generalize to the pure software project I’m working on today. A lot of the meta-skills I learned transfer over pretty well, though.
If I had to pick the three most useful meta-skills I learned back then, I’d say they were debugging, bug tracking, and figuring out how to approach hard problems.
Debugging is a funny skill to claim to have because everyone thinks they know how to debug. For me, I wouldn’t even say that I learned how to debug at Centaur, but that I learned how to be persistent. Non-deterministic hardware bugs are so much worse than non-deterministic software bugs that I always believe I can track down software bugs. In the absolute worst case, when there’s a bug that isn’t caught in logs and can’t be caught in a debugger, I can always add tracing information until the bug becomes obvious. The same thing’s true in hardware, but “recompiling” to add tracing information takes 3 months per “recompile”; compared to that experience, tracking down a software bug that takes three months to figure out feels downright pleasant.
Bug tracking is another meta-skill that everyone thinks they have, but when when I look at most projects I find that they literally don’t know what bugs they have and they lose bugs all the time due to a failure to triage bugs effectively. I didn’t even know that I’d developed this skill until after I left Centaur and saw teams that don’t know how to track bugs. At Centaur, depending on the phase of the project, we’d have between zero and a thousand open bugs. The people I worked with most closely kept a mental model of what bugs were open; this seemed totally normal at the time, and the fact that a bunch of people did this made it easy for people to be on the same page about the state of the project and which areas were ahead of schedule and which were behind.
Outside of Centaur, I find that I’m lucky to even find one person who’s tracking what the major outstanding bugs are. Until I’ve been on the team for a while, people are often uncomfortable with the idea of taking a major problem and putting it into a bug instead of fixing it immediately because they’re so used to bugs getting forgotten that they don’t trust bugs. But that’s what bug tracking is for! I view this as analogous to teams whose test coverage is so low and staging system is so flaky that they don’t trust themselves to make changes because they don’t have confidence that issues will be caught before hitting production. It’s a huge drag on productivity, but people don’t really see it until they’ve seen the alternative.
Perhaps the most important meta-skill I picked up was learning how to solve large problems. When I joined Centaur, I saw people solving problems I didn’t even know how to approach. There were folks like Glenn Henry, a fellow from IBM back when IBM was at the forefront of computing, and Terry Parks, who Glenn called the best engineer he knew at IBM. It wasn’t that they were 10x engineers; they didn’t just work faster. In fact, I can probably type 10x as quickly as Glenn (a hunt and peck typist) and could solve trivial problems that are limited by typing speed more quickly than him. But Glenn, Terry, and some of the other wizards knew how to approach problems that I couldn’t even get started on.
I can’t cite any particular a-ha moment. It was just eight years of work. When I went looking for problems to solve, Glenn would often hand me a problem that was slightly harder than I thought possible for me. I’d tell him that I didn’t think I could solve the problem, he’d tell me to try anyway, and maybe 80% of the time I’d solve the problem. We repeated that for maybe five or six years before I stopped telling Glenn that I didn’t think I could solve the problem. Even though I don’t know when it happened, I know that I eventually started thinking of myself as someone who could solve any open problem that we had.
Grad school, again (2008 - 2010)
At some point during my tenure at Centaur, I switched to being part-time and did a stint taking classes and doing a bit of research at the local university. For reasons which I can’t recall, I split my time between software engineering and CS theory.
I read a lot of software engineering papers and came to the conclusion that we know very little about what makes teams (or even individuals) productive, and that the field is unlikely to have actionable answers in the near future. I also got my name on a couple of papers that I don’t think made meaningful contributions to the state of human knowledge.
On the CS theory side of things, I took some graduate level theory classes. That was genuinely educational and I really “got” algorithms for the first time in my life, as well as complexity theory, etc. I could have gotten my name on a paper that I didn’t think made a meaningful contribution to the state of human knowledge, but my would-be co-author felt the same way and we didn’t write it up.
I originally tried grad school again because I was considering getting a PhD, but I didn’t find the work I was doing to be any more “interesting” than the work I had at Centaur, and after seeing the job outcomes of people in the program, I decided there was less than 1% chance that a PhD would provide any real value to me and went back to Centaur full time.
After eight years at Centaur, I wanted to do something besides microprocessors. I had enough friends at other hardware companies to know that I’d be downgrading in basically every dimension except name recognition if I switched to another hardware company, so I started applying to software jobs.
While I was applying to jobs, I heard about RC. It sounded great, maybe even too great: when I showed my friends what people were saying about it, they thought the comments were fake. It was a great experience, and I can see why so many people raved about it, to the point where real comments sound impossibly positive. It was transformative for a lot of people; I heard a lot of exclamations like “I learned more here in 3 months here than in N years of school” or “I was totally burnt out and this was the first time I’ve been productive in a year”. It wasn’t transformative for me, but it was as fun a 3 month period as I’ve ever had, and I even learned a thing or two.
From a learning standpoint, the one major thing I got out of RC was feedback from Marek, whom I worked with for about two months. While the freedom and lack of oversight at Centaur was great for letting me develop my ability to work independently, I basically didn’t get any feedback on my work since they didn’t do code review while I was there, and I never really got any actionable feedback in performance reviews.
Marek is really great at giving feedback while pair programming, and working with him broke me of a number of bad habits as well as teaching me some new approaches for solving problems. At a meta level, RC is relatively more focused on pair programming than most places and it got me to pair program for the first time. I hadn’t realized how effective pair programming with someone is in terms of learning how they operate and what makes them effective. Since then, I’ve asked a number of super productive programmers to pair program and I’ve gotten something out of it every time.
Second real job (2013 - 2014)
I was in the right place at the right time to land on a project that was just transitioning from Andy Phelps’ pet 20% time project into what would later be called the Google TPU.
As far as I can tell, it was pure luck that I was the second engineer on the project as opposed to the fifth or the tenth. I got to see what it looks like to take a project from its conception and turn it into something real. There was a sense in which I got that at Centaur, but every project I worked on was either part of a CPU, or a tool whose goal was to make CPU development better. This was the first time I worked on a non-trivial project from its inception, where I wasn’t just working on part of the project but the whole thing.
That would have been educational regardless of the methodology used, but it was a particularly great learning experience because of how the design was done. We started with a lengthy discussion on what core algorithm we were going to use. After we figured out an algorithm that would give us acceptable performance, we coded up design docs for every major module before getting serious about implementation.
Many people consider writing design docs to be a waste of time nowadays, but going through this process, which took months, had a couple big advantages. The first is that working through a design collaboratively teaches everyone on the team everyone else’s tricks. It’s a lot like the kind of skill transfer you get with pair programming, but applied to design. This was great for me, because as someone with only a decade of experience, I was one of the least experienced people in the room.
The second is that the iteration speed is much faster in the design phase, where throwing away a design just means erasing a whiteboard. Once you start coding, iterating on the design can mean throwing away code; for infrastructure projects, that can easily be person-years or even tens of persons-years of work. Since working on the TPU project, I’ve seen a couple of teams on projects of similar scope insist on getting “working” code as soon as possible. In every single case, that resulted in massive delays as huge chunks of code had to be re-written, and in a few cases the project was fundamentally flawed in a way that required the team had to start over from scratch.
I get that on product-y projects, where you can’t tell how much traction you’re going to get from something, you might want to get an MVP out the door and iterate, but for pure infrastructure, it’s often possible to predict how useful something will be in the design phase.
The other big thing I got out of the job was a better understanding of what’s possible when a company makes a real effort to make engineers productive. Something I’d seen repeatedly at Centaur was that someone would come in, take a look around, find the tooling to be a huge productivity sink, and then make a bunch of improvements. They’d then feel satisfied that they’d improved things a lot and then move on to other problems. Then the next new hire would come in, have the same reaction, and do the same thing. The result was tools that improved a lot while I was there, but not to the point where someone coming in would be satisfied with them. Google was the only place I’d worked where a lot of the tools seem like magic compared to what exists in the outside world. Sure, people complain that a lot of the tooling is falling over, that there isn’t enough documentation, and that a lot of it is out of date. All true. But the situation is much better than it’s been at any other company I’ve worked at. That doesn’t seem to actually be a competitive advantage for Google’s business, but it makes the development experience really pleasant.
Third real job (2015 - Present)
It’s hard for me to tell what I’ve learned until I’ve had a chance to apply it elsewhere, so this section is a TODO until I move onto another role. I feel like I’m learning a lot right now, but I’ve noticed that feeling like I’m learning a lot at the time is weakly correlated to whether or not I learn skills that are useful in the long run. Unless I get re-org’d or someone makes me an offer I can’t refuse, it seems unlikely that I’d move on until my current project is finished, which seems likely to be at least another 6-12 months.
What about the bad stuff?
When I think about my career, it seems to me that it’s been one lucky event after the next. I’ve been unlucky a few times, but I don’t really know what to take away from the times I’ve been unlucky.
For example, I’d consider my upbringing to be mildly abusive. I remember having nights where I couldn’t sleep because I’d have nightmares about my father every time I fell asleep. Being awake during the day wasn’t a great experience, either. That’s obviously not good, and in retrospect it seems pretty directly related to the academic problems I had until I moved out, but I don’t know that I could give useful advice to a younger version of myself. Don’t be born into an abusive family? That’s something people would already do if they had any control over the matter.
Or to pick a more recent example, I once joined a team that scored a 1 on the Joel Test. The Joel Test is now considered to be obsolete because it awards points for things like “Do you have testers?” and “Do you fix bugs before writing new code?”, which aren’t considered best practices by most devs today. Of the items that aren’t controversial, many seem so obvious that they’re not worth asking about, things like:
- Can you make a build in one step?
- Do you make daily builds?
- Do you have a bug database?
- Do new candidates write code during their interview?
For anyone who cares about this kind of thing, it’s clearly not a great idea to join a team that does, at most, 1 item off of Joel’s checklist. Getting first-hand experience on a team that scored a 1 didn’t give me any new information that would make me reconsider my opinion.
You might say that I should have asked about those things. It’s true! I should have, and I probably will in the future. However, when I was hired, the TL who was against version control and other forms of automation hadn’t been hired yet, so I wouldn’t have found out about this if I’d asked. Furthermore, even if he’d already been hired, I’m still not sure I would have found out about it – this is the only time I’ve joined a team and then found that most of the factual statements made during the recruiting process were untrue. When I was on that team, every day featured a running joke between team members about how false the recruiting pitch was.
I could try to prevent similar problems in the future by asking for concrete evidence of factual claims (e.g., if someone claims the attrition rate is X, I could ask for access to the HR database to verify), but considering that I have a finite amount of time and the relatively low probability of being told outright falsehoods, I think I’m going to continue to prioritize finding out other information when I’m considering a job and just accept that there’s a tiny probability I’ll end up in a similar situation in the future.
When I look at the bad career-related stuff I’ve experienced, almost all of it falls into one of two categories: something obviously bad that was basically unavoidable, or something obviously bad that I don’t know how to reasonably avoid, given limited resources. I don’t see much to learn from that. That’s not to say that I haven’t made and learned from mistakes. I’ve made a lot of mistakes and do a lot of things differently as a result of mistakes! But my worst experiences have come out of things that I don’t know how to prevent in any reasonable way.
This also seems to be true for most people I know. For example, something I’ve seen a lot is that a friend of mine will end up with a manager whose view is that managers are people who dole out rewards and punishments (as opposed to someone who believes that managers should make the team as effective as possible, or someone who believes that managers should help people grow). When you have a manager like that, a common failure mode is that you’re given work that’s a bad fit, and then maybe you don’t do a great job because the work is a bad fit. If you ask for something that’s a better fit, that’s refused (why should you be rewarded with doing something you want when you’re not doing good work, instead you should be punished by having to do more of this thing you don’t like), which causes a spiral that ends in the person leaving or getting fired. In the most recent case I saw, the firing was a surprise to both the person getting fired and their closest co-workers: my friend had managed to find a role that was a good fit despite the best efforts of management; when management decided to fire my friend, they didn’t bother to consult the co-workers on the new project, who thought that my friend was doing great and had been doing great for months!
I hear a lot of stories like that, and I’m happy to listen because I like stories, but I don’t know that there’s anything actionable here. Avoid managers who prefer doling out punishments to helping their employees? Obvious but not actionable.
Conclusion
The most common sort of career advice I see is “you should do what I did because I’m successful”. It’s usually phrased differently, but that’s the gist of it. That basically never works. When I compare notes with friends and acquaintances, it’s pretty clear that my career has been unusual in a number of ways, but it’s not really clear why.
Just for example, I’ve almost always had a supportive manager who’s willing to not only let me learn whatever I want on my own, but who’s willing to expend substantial time and effort to help me improve as an engineer. Most folks I’ve talked to have never had that. Why the difference? I have no idea.
One story might be: the two times I had unsupportive managers, I quickly found other positions, whereas a lot of friends of mine will stay in roles that are a bad fit for years. Maybe I could spin it to make it sound like the moral of the story is that you should leave roles sooner than you think, but both of the bad situations I ended up in, I only ended up in because I left a role sooner than I should have, so the advice can’t be “prefer to leave roles sooner than you think”. Maybe the moral of the story should be “leave bad roles more quickly and stay in good roles longer”, but that’s so obvious that it’s not even worth stating. Every strategy that I can think of is either incorrect in the general case, or so obvious there’s no reason to talk about it.
Another story might be: I’ve learned a lot of meta-skills that are valuable, so you should learn these skills. But you probably shouldn’t. The particular set of meta-skills I’ve picked have been great for me because they’re skills I could easily pick up in places I worked (often because I had a great mentor) and because they’re things I really strongly believe in doing. Your circumstances and core beliefs are probably different from mine and you have to figure out for yourself what it makes sense to learn.
Yet another story might be: while a lot of opportunities come from serendipity, I’ve had a lot of opportunities because I spend a lot of time generating possible opportunities. When I passed around the draft of this post to some friends, basically everyone told me that I emphasized luck too much in my narrative and that all of my lucky breaks came from a combination of hard work and trying to create opportunities. While there’s a sense in which that’s true, many of my opportunities also came out of making outright bad decisions.
For example, I ended up at Centaur because I turned down the chance to work at IBM for a terrible reason! At the end of my internship, my manager made an attempt to convince me to stay on as a full-time employee, but I declined because I was going to grad school. But I was only going to grad school because I wanted to get a microprocessor logic design position, something I thought I couldn’t get with just a bachelor’s degree. But I could have gotten that position if I hadn’t turned my manager down! I’d just forgotten the reason that I’d decided to go to grad school and incorrectly used the cached decision as a reason to turn down the job. By sheer luck, that happened to work out well and I got better opportunities than anyone I know from my intern cohort who decided to take a job at IBM. Have I “mostly” been lucky or prepared? Hard to say; maybe even impossible.
Careers don’t have the logging infrastructure you’d need to determine the impact of individual decisions. Careers in programming, anyway. Many sports now track play-by-play data in a way that makes it possible to try to determine how much of success in any particular game or any particular season was luck and how much was skill.
Take baseball, which is one of the better understood sports. If we look at the statistical understanding we have of performance today, it’s clear that almost no one had a good idea about what factors made players successful 20 years ago. One thing I find particularly interesting is that we now have much better understanding of which factors are fundamental and which factors come down to luck, and it’s not at all what almost anyone would have thought 20 years ago. We can now look at a pitcher and say something like “they’ve gotten unlucky this season, but their foo, bar, and baz rates are all great so it appears to be bad luck on balls in play as opposed any sort of decline in skill”, and we can also make statements like “they’ve done well this season but their fundamental stats haven’t moved so it’s likely that their future performance will be no better than their past performance before this season”. We couldn’t have made a statement like that 20 years ago. And this is a sport that’s had play-by-play video available going back what seems like forever, where play-by-play stats have been kept for a century, etc.
In this sport where everything is measured, it wasn’t until relatively recently that we could disambiguate between fluctuations in performance due to luck and fluctuations due to changes in skill. And then there’s programming, where it’s generally believed to be impossible to measure people’s performance and the state of the art in grading people’s performance is that you ask five people for their comments on someone and then aggregate the comments. If we’re only just now able to make comments on what’s attributable to luck and what’s attributable to skill in a sport where every last detail of someone’s work is available, how could we possibly be anywhere close to making claims about what comes down to luck vs. other factors in something as nebulous as a programming career?
In conclusion, life is messy and I don’t have any advice.
Documentation
I once worked with Jared Davis, a documentation wizard whose documentaiton was so good that I’d go to him to understand how a module worked before I talked to the owner the module. As far as I could tell, he wrote documentation on things he was trying to understand to make life easier for himself, but his documentation was so good that was it was a force multiplier for the entire company.
Later, at Google, I noticed a curiously strong correlation between the quality of initial design docs and the success of projects. Since then, I’ve tried to write solid design docs and documentation for my projects, but I still have a ways to go.
So far, I’ve only landed on teams where things are much better than average and on teams where things are much worse than average. You might think that, because there’s so much low hanging fruit on teams that are much worse than average, it should be easier to improve things on teams that are terrible, but it’s just the opposite. The places that have a lot of problems have problems because something makes it hard to fix the problems.
When I joined the team that scored a 1 on the Joel Test, it took months of campaigning just to get everyone to use version control.
I’ve never seen an enviroment go from “bad” to “good” and I’d be curious to know what that looks like and how it happens. Yossi Kreinin’s thesis is that only management can fix broken situations. That might be true, but I’m not quite ready to believe it just yet, even though I don’t have any evidence to the contrary.
Appendix B: other “how I became a programmer” stories
Kragen. Describes 27 years of learning to program. Heavy emphasis on conceptual phases of development (e.g., understanding how to use provided functions vs. understanding that you can write arbitrary functions)
Julia Evans. Started programming on a TI-83 in 2004. Dabbled in programing until college (2006-2011) and has been working as a professional programmer ever since. Some emphasis on the “journey” and how long it takes to improve.
Tavish Armstrong. 4th grade through college. Emphasis on particular technologies (e.g., LaTeX or Python).
Caitie McCaffrey
. Started programming in AP computer science. Emphasis on how interests led to a career in programming.
Matt DeBoard. Spent 12 weeks learning Django with the help of a mentor. Emphasis on the fact that it’s possible to become a programmer without programming background.
Kristina Chodorow. Started in college. Emphasis on alternatives (math, grad school).
Michael Bernstein. Story of learning Haskell over the course of years. Emphasis on how long it took to become even minimally proficient.
Thanks to Leah Hanson, Lindsey Kuper, Kelley Eskridge, Jeshua Smith, Tejas Sapre, Joe Wilder, Adrien Lamarque, Maggie Zhou, Lisa Neigut, Steve McCarthy, Darius Bacon, Kaylyn Gibilterra, and Sarah Ransohoff for comments/criticism/discussion.